
报告错误
如果你发现该网页中存在错误/显示异常,可以从以下两种方式向我们报告错误,我们会尽快修复:
- 使用 CS Club 网站错误 为主题,附上错误截图或描述及网址后发送邮件到 286988023@qq.com
- 在我们的网站代码仓库中创建一个 issue 并在 issue 中描述问题 点击链接前往Github仓库

三种不同的 CV 任务
一般来说,我们可以将 CV 任务按照输出的数据量分为以下三种:
- 图像分类 - 给定一张图片,输出一个一维向量,对整张图片进行分类
- 物体识别 - 给定一张照片,输出若干坐标对,在照片上用方形的 box 框出所有特定类型的物体
- 图像分割 - 给定一张照片,输出一个同样大小的 mask,标注具体每一个像素属于什么类型
这三种任务中,模型输出的信息量是递增的。R-CNN (Regions with CNN features) 是第一个使用神经网络的物体识别模型 - 在 PASCAL VOC 2010 数据集中,模型将 mAP (mean Average Precision) 的值从之前最好的 $35.1\%$ 一举提升到了 $53.7\%$。这篇文章接下来会详细解读 R-CNN 的论文 Rich feature hierarchies for accurate object detection and semantic segmentation。后来许多的模型都基于这个模型的改进 - 例如 Fast R-CNN, Faster R-CNN 等。
在 R-CNN 之前的物体识别模型
在 R-CNN 出现前,主要有两种做 Object Detection 的模型 - 第一种是将寻找 box 的位置作为一个回归问题来处理的,第二种则是使用一个滑动窗口用 CNN 一个个判别 window 中的内容是否是一个特定的类别。这两种方法最终结果的精度与速度都无法和 R-CNN 相比。
模型结构
R-CNN 模型可以分为三个部分
- 类型无关的候选区域生成 - 提供一系列(区域无关的)的候选区域让识别器进行识别
- 使用 CNN 对候选区域进行特征提取
- 对 CNN 提取出的特征向量使用每个分类单独训练的 SVM 进行具体分类
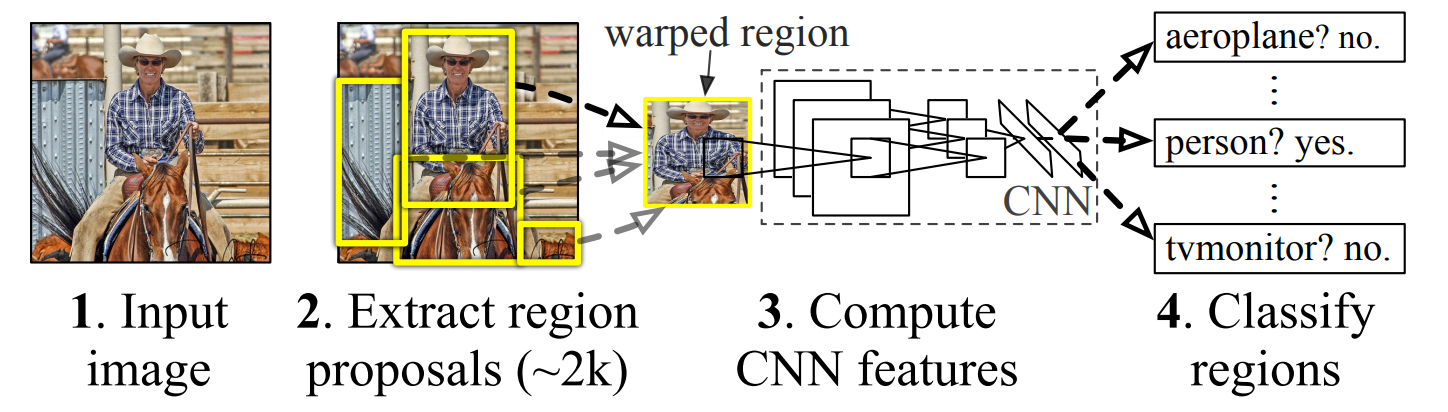
1 - 候选区域生成
对于一张任意尺寸的输入图片,R-CNN 会先使用 Selective Search 算法对图片中所有的像素进行聚类分析 - 相似颜色/纹路的像素被合并为同一个区域,如果区域的面积足够大 Selective Search 就会认为这一片区域可能有物体并将这个(矩形)区域作为一个 Region Proposal 传递到下一步。需要注意的是,在这一步中,Selective Search 算法不会对自己输出的 Region Proposal 进行任何物体类型识别,算法本身也没有关于物体分类的先验知识。因此,这一步返回的候选区域被称为 Category-independent Region Proposal (类型无关区域提案)。更多关于 Selective Search 的信息
在 R-CNN 中,模型会从一张图片中提取 2000 个候选区域进行接下来的特征提取和物体识别。
2 - 候选区域特征提取
对于每一个输入的候选区域,模型会使用一个 由5个卷积层和2个全连接层构成的 CNN 进行特征提取,将一个输入的候选区域转化为 $1\times 4096$ 维的特征向量。
Selective Search 的输出是任意尺寸的矩形,但是 CNN 要求输入一定是 $227\times 227$ 的尺寸。为了解决这个问题,作者尝试了三种方式将 Region Proposal 转化为 $227\times 227$ 的尺寸:
- Tightest-square with Context 在矩形的 Region Proposal 把框变为正方形产生 CNN 的输入图片。
- Tightest-square without Context 直接用空白填充 Region Proposal 和目标的 $227 \times 227$ 正方形之间的空袭
- Wrap 直接将 Region Proposal 各向异性的(也就是说照片的各个轴缩放系数不同)缩放为 $227\times 227$ 的正方形

(i) Tightest-square with Context, (ii) Tightest-square without Context, (iii) Wrap
最后选择使用 wrap 的方法直接将 Region Proposal 转化为 CNN 接受的尺寸
除了 wrap 以外,作者还对所有的 Region Proposal 加上了 16 个像素的 Padding - 在 Region Proposal 外围加上厚度 16 个像素的边框来收集 Proposal 周围的环境信息。
R-CNN 使用的特征提取 CNN 拥有 5 个卷积与池化层和 2 个全连接层。
3 - SVM 分类 CNN 提取出的特征向量
2000 张输入的 $227\times 227$ 的照片被 CNN 处理为 $1\times 4096$ 的特征向量后,我们可以将它们合并为一个 $2000\times 4096$ 的特征矩阵,并使用 SVM 对这个特征矩阵的每一个行向量(每个特征向量)进行分类。假如有 $N$ 个 class,则 $N$ 个 SVM 的权重向量可以合并为一个 $4096 \times N$ 的权重矩阵。通过矩阵相乘,我们可以快速的判定每一个 Region Proposal 属于哪个类。
R-CNN 的优势
- 无论要求模型进行多少分类的任务,花费在 Region Proposal 和 特征提取上的时间都是一致的,同时,CNN 特征提取的参数对于所有 SVM 是共享的,这可以大大减少参数量和运算量
- 模型中间部分的 CNN 特征提取极大的缩减了每个 Region proposal 的特征向量维度,让第三部分 SVM 分类更加具备可拓展性。(因为只有 4096 维,所以就算是 100k 分类问题 R-CNN 也只需要占用 1.5G 内存,而之前的 UVA 模型则需要占用 134 G 内存)
输出优化
模型输出 2000 个 box,每个 box 拥有自己的分类和分值(来自于 SVM, background 也算一个类型)。为了防止出现多个 box 框定同一个物体的情况,作者对 R-CNN 的输出做出了优化 - 如果两个框有重叠部分,并且 box 之间的 交并比 (Intersection Over Union, IOU) 超过一个训练得到的数值,就删除两个 box 中得分较低的 box。
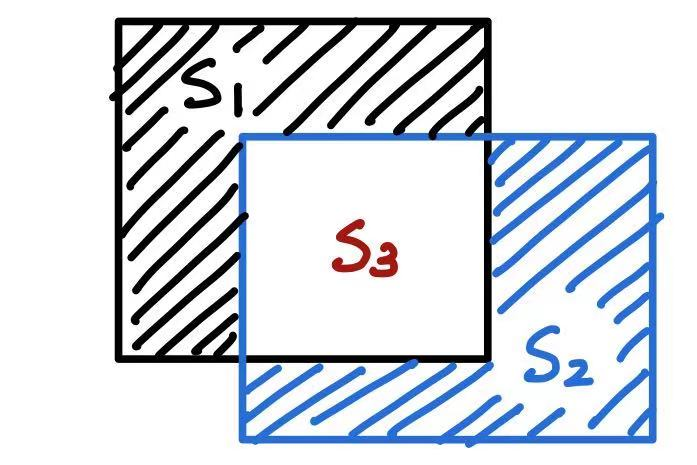
黑色矩形与蓝色矩形的 IOU 值
\[IOU = \frac{\text{Black }\cap\text{ Blue}}{\text{Black }\cup \text{ Blue}} = \frac{S_3}{S_1 + S_2 + S_3}\]
模型训练
这里只讲述模型的 CNN 特征提取部分的训练方法
监督预训练
CNN 模型一开始在 ILSVRC2012 数据集上进行有监督的预训练。这个数据集的数据量较大,但是没有物体的 box 标签,只有图像分类标签。在多个 epoch 的训练后,CNN 达到与 Krizhevsky et al. 相似的准确率(稍低 $2.2\%$)。
特定领域微调
在 CNN 模型完成有监督预训练后,作者对模型进行了微调。作者通过提供给 CNN 已经调整完尺寸的 Region Proposal 来进一步训练模型。在这个过程中,模型的学习率被设定为 $0.001$ - 预训练过程中的 $1/10$,通过设置较小的学习率,模型不会在微调过程中破坏在预训练过程中习得的特征提取参数。
在生成微调使用的数据集时,作者将所有与标记 box 的 IOU 值大于等于 0.5 的 box 都当作同样的分类 box。通过这种方法,作者手动将物体识别的数据集增大了 30 倍。
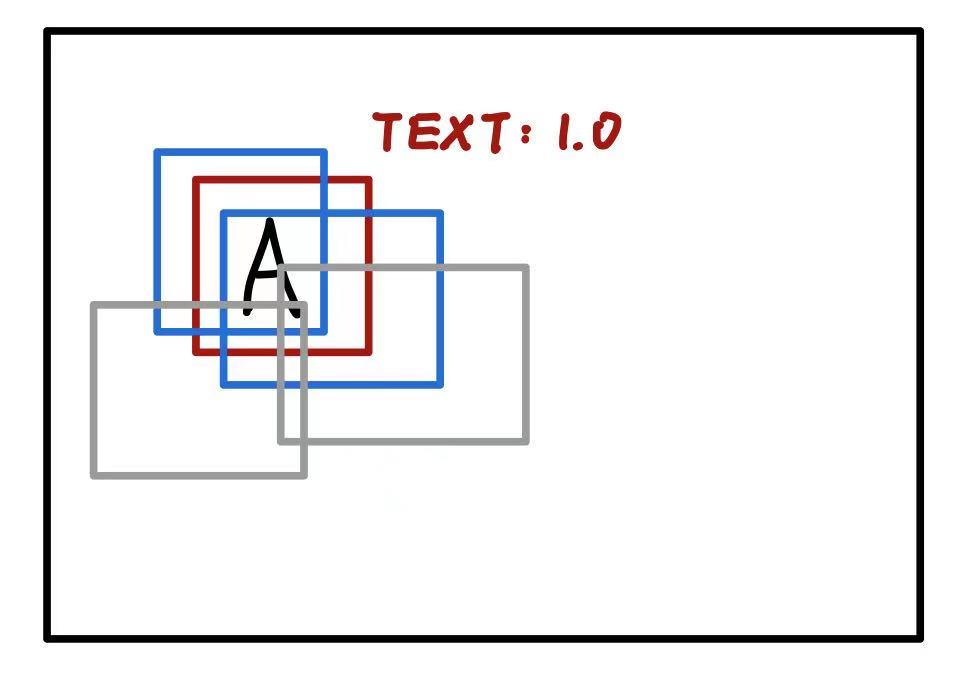
在上面的图中,红色的框是人工标记的 Ground Truth,蓝色的框因为与红框的 IOU 值 $\geq 0.5$,所以也被认为是标记 Text 的 box。灰色的框因为与红框的 IOU 小于 0.5,所以不能够被看作是标记 Text 的框
分层研究 (Ablation Study)
作者对 R-CNN 中各层的输出结果做了研究与比较,结果说明:
在预训练过程中
- 最后一层全连接层的泛化能力比倒数第二层差 - 这意味着在这个阶段删除最后一个全连接层 $fc_7$,即缩减模型 $29\%$ 的参数后模型的表现不会劣化
- 在移除最后两层全连接层以后,CNN 模型只使用卷积和池化层(约占整个模型参数量的 $6\%$)依然可以达到较好的效果
在微调过程中
- 模型的物体识别准确率 (mAP) 提升了 $8\%$
- 研究发现模型识别准确率的提升主要来自于 $fc_6$ 与 $fc_7$ 这两个全连接层的参数更新
- 这说明最后一个池化层(倒数第三层)从预训练数据集中学习到的特征提取参数拥有泛用性,模型的提升来自于基于模型前面卷积与池化提取出的特征进行推断的分类器的训练。
